Der Menüpunkt »Optionen« - »Fremdsprache« steht nur im erweiterten Modus zur Verfügung.
Die Erkennung fremdsprachiger Texte basiert auf folgender Überlegung:
- Bei normalen deutsch-sprachigen Texten wird aufgrund des Wörterbuches und der Parser eine gewisse Anzahl von Worten erkannt und in der Anzeige mit einem »*« versehen. Das Verhältnis von erkannten Worten zur Gesamtanzahl der Worte wird für jede im »Dateien«-Fenster angezeigte Datei als Prozentzahl in der rechten Spalte angegeben.
- Bei fremdsprachigen Texten und bei Sondertexten (Adreßbücher, die großenteils Eigennamen und Straßen enthalten, oder bei Dokumentationen von Computer-Quell-Programmen etc.) werden deutlich weniger Worte erkannt werden, so daß sich die Erkennungsquote stark vermindert.
- Daher liegt es nahe, durch Festlegen einer Mindest-Erkennungsquote fremdsprachige Dokumente und Sondertexte von normalen deutsch-sprachigen zu unterscheiden. Auf Wunsch können daher innerhalb eines Indexes
- alle Dokumente,
- nur normale deutsch-sprachige Dokumente, oder
- nur fremdsprachige Dokumente und Sondertexte
zur Anzeige gebracht werden.
Nach dieser einleitenden Vorüberlegung folgt nun die praktische Anwendung:
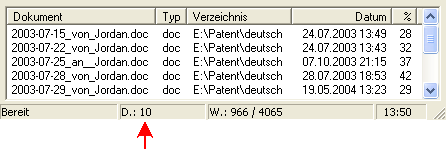
- In einem Index mögen 13 Dokumente das Wort »Patent« enthalten:
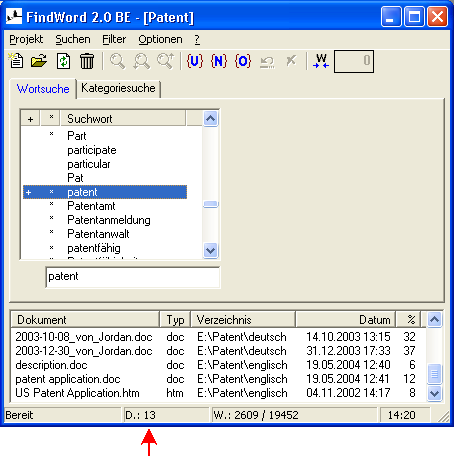
- Die »Erkennungsquote« gibt für das aktuellen Index in Prozent an, wieviele Wörter einer Datei vom Wörterbuch oder einem Parser erkannt sein müssen, um diese Datei als normales deutsch-sprachiges Dokument zu interpretieren.
Üblicherweise werden bei
- normalen deutsch-sprachigen Dokumente mehr als 30% und bei
- fremdsprachigen Dokumenten oder Sondertexten weniger als 15%
der Worte erkannt. Daher empfiehlt sich als Erkennungsquote ein Wert im Bereich von 20%.
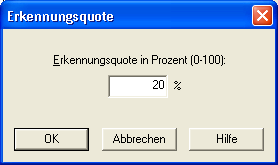
- Wenn nun die Erkennungsquote auf 20% gesetzt und »Nur fremdsprachige Dateien« ausgewählt wird,

werden bei obigem Beispiel 3 englische Dokumente gefunden, deren Erkennungsquoten von 6%, 12% und 8% unter den eingestellten 20% liegen:
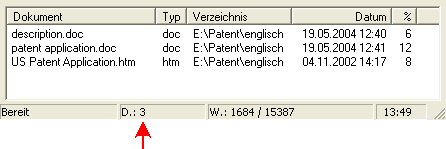
Demnach müssen sich bei Wahl von »Nur deutschsprachige Dateien«

13-3 = 10 Dateien ergeben, deren Erkennungsquote mindestens 20% beträgt:
Details für Technik-Interessierte:
Die Berechnungsformel für die Erkennungsquote lautet »Erkennungsquote = 100 * (gefundene Wörter) / (Gesamtzahl aller Wörter)«, wobei jedes Wort auch dann einzeln zählt, wenn es identisch mehrfach vorkommt.
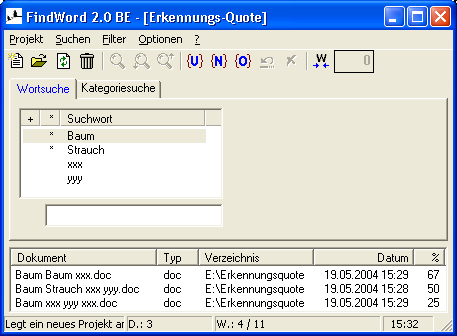
Beispiel für die rechnerische Ermittelung der Erkennungsquote:
Es wird angenommen, daß die Worte »Baum« und »Strauch« vom Wörterbuch erfaßt werden, die Worte »xxx« und »yyy« dagegen nicht.
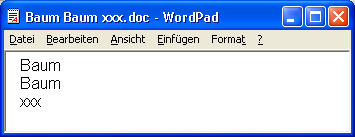
- Wenn eine Datei aus den Wörtern »Baum Baum xxx« besteht, enthält sie 2 gefundene Wörter und insgesamt 3 Wörter, so daß sich die Erkennungsquote errechnet zu 100 * 2 / 3 = 67 %.
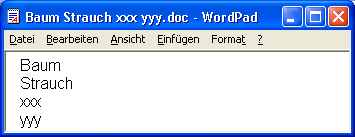
- Wenn eine Datei aus den Wörtern »Baum Strauch xxx yyy« besteht, enthält sie 2 gefundene Wörter und insgesamt 4 Wörter, so daß sich die Erkennungsquote errechnet zu 100 * 2 / 4 = 50 %.
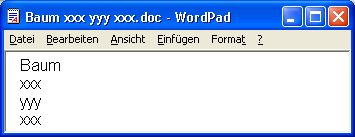
- Wenn eine Datei aus den Wörtern »Baum xxx yyy xxx« besteht, enthält sie 1 gefundenes Wort und insgesamt 4 Wörter, so daß sich die Erkennungsquote errechnet zu 100 * 1 / 4 = 25 %.
In FindWord sieht das Ganze dann so aus: